

@inproceedings{shi2025zeromimic,
title={ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos},
author={Junyao Shi and Zhuolun Zhao and Tianyou Wang and Ian Pedroza and Amy Luo and Jie Wang and Jason Ma and Dinesh Jayaraman},
year={2025},
booktitle={International Conference on Robotics and Automation (ICRA)},
}Robots require demonstrations on the same robot, in the same room, with the same objects, which scales poorly.
Can robots learn general skill policies without specific reference to one robot, scene, or object from more diverse and larger sources of data?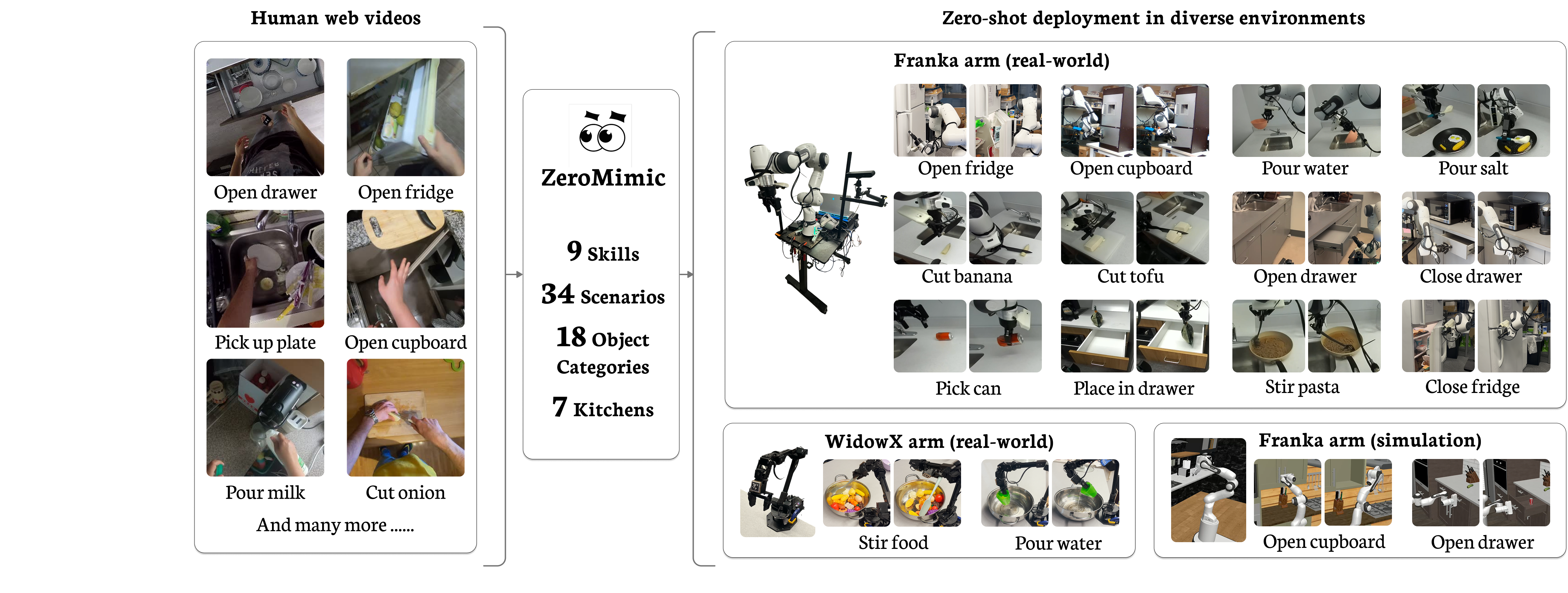
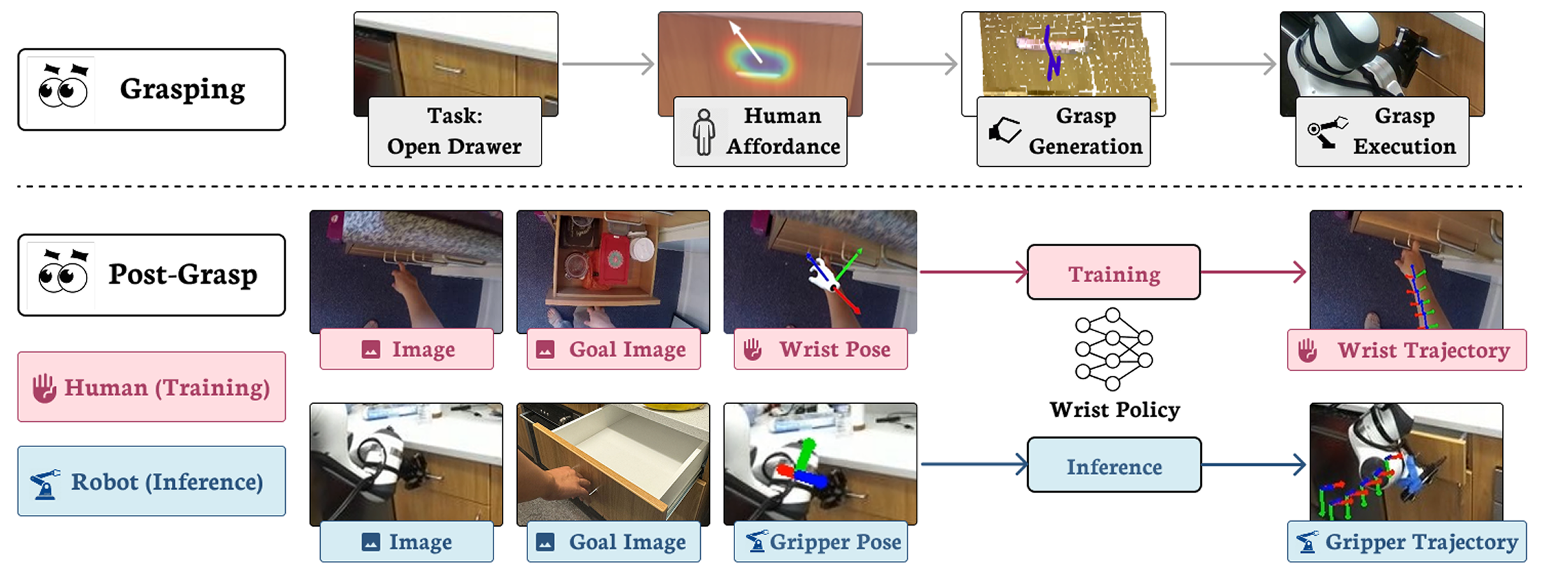
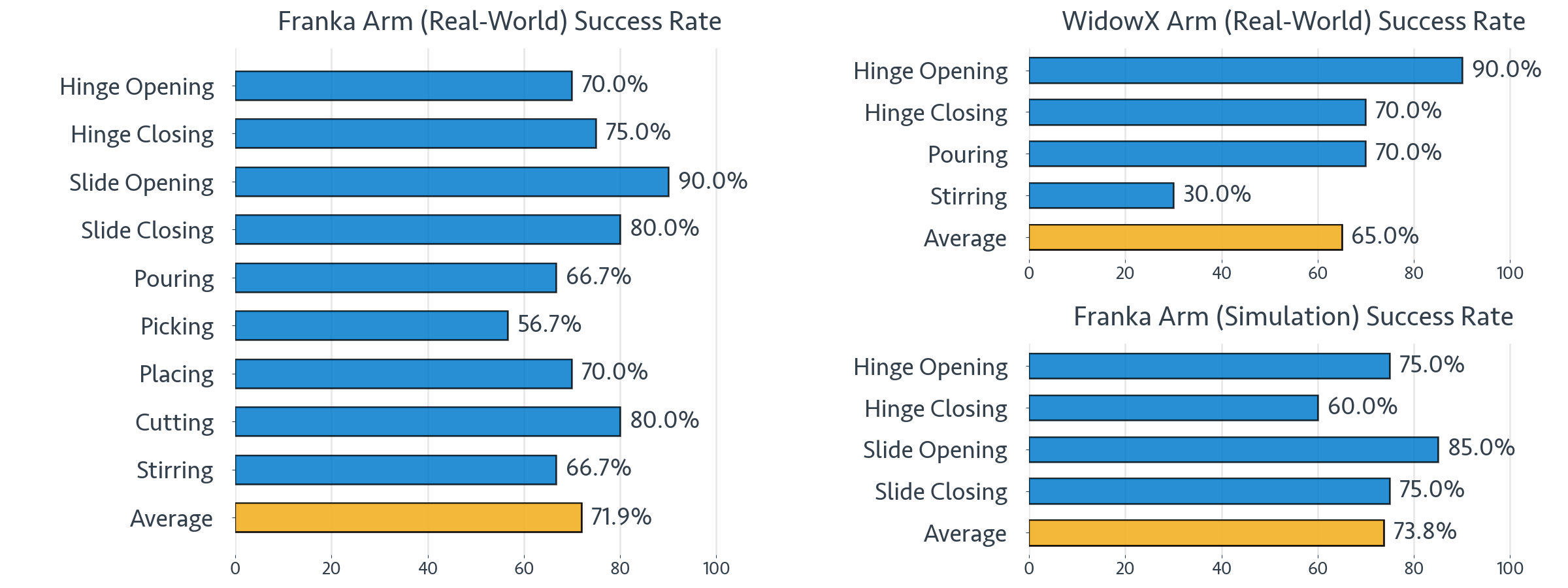
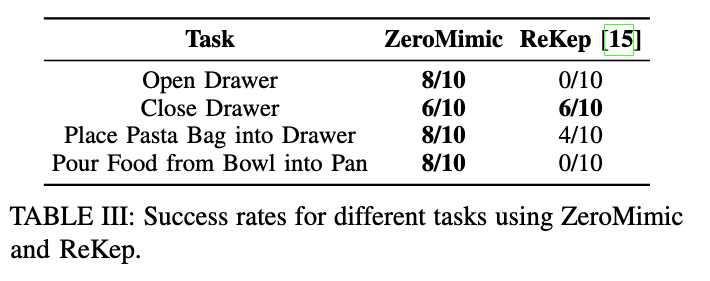
We introduce ZeroMimic, a system that distills robotic manipulation skills from egocentric human web videos for zero-shot deployment in diverse real-world and simulated environments, a variety of objects, and different robot embodiments. Critically, ZeroMimic learns purely from passive human videos and does not require any robot data.